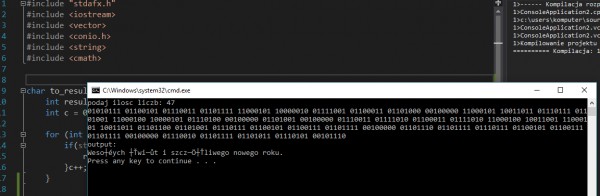
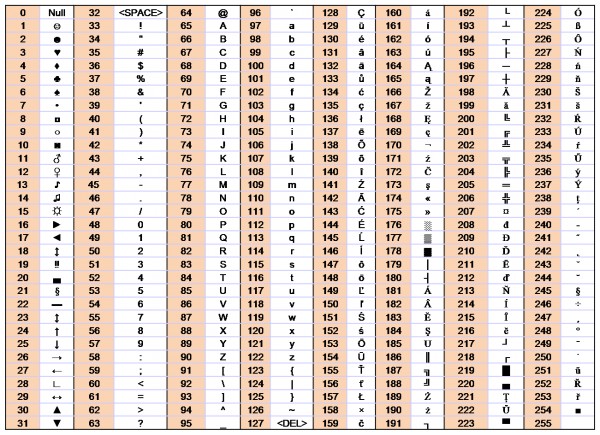
Hej, wiem że jako tako jest dużo pytań na temat polskich znaków, nie znalazłem jednak nic co by mi działało :X. Mianowicie koledzy ze szkoły "udając mądrych" pisali życzenia w systemie binarnym, ja by stać się jeszcze mądrzejszym (po tym pytaniu widać że tak nie jest) napisałem program konwertujący znaki zapisane w systemie binarnym na zrozumiały tekst. O ile bez jakiś większych problemów zrobiłem interpreter bin->dec (i wszystko działa tu ok) to zniszczyła mnie ta kwestia kodowania znaków... Korzystałem z takiej tabeli ASCI (zastępowałem znaki polskie odpowiednimi ich kodami):
Okazało się jednak że tekst był zapisany z wykorzystaniem UTF-8, moje IDE go nie obsługuje (nie wiem gdzie w ogóle zmienić kodowanie). Zrobiłem masę if'ów przetwarzających kod polskich symboli z UTF-8 na tą tabelkę która mi działa poprawnie. To jednak nic nie daje, korzystałem z mnóstwa instrukcji i funkcji (local, global, wchar, wcout itd...) Nic jednak u mnie nie działa. Jakaś masakra, pokonałem problem jakim było stworzenie algorytmu przeliczającego systemy a teraz wysiadam przy systemach kodowania. Czy jest jakiś sensowny sposób by pozbyć się tego problemu. Czy na prawdę w XXI wieku są kłopoty z kodowaniem znaków? Że trzeba robić funkcje, makra itd... Wiem że to ja tego w ogóle nie rozumiem i to raczej moja wina, będę wam bardzo wdzięczny za pomoc . Reasumując chcę by program kodował znaki w UTF-8 w tym polskie.
Przepraszam jeśli coś źle napisałem i jeszcze raz dziękuje za chęć pomocy :) :
#include "stdafx.h"
#include <iostream>
#include <vector>
#include <conio.h>
#include <string>
#include <cmath>
char to_result(std::string str_bin) { //konwersja dziala ok ale:
int result = 0;
int c = 0;
for (int i = str_bin.length() - 1; i >= 0; i--) {
if(str_bin[i]!='0'){
result += pow(2, c);
}c++;
}
return char(result); //tu probowalem wiele metod, mialem tu z 20 if'ow ale skasowalem. Tutaj zwracamy odpowiedni znak w zaleznosci od liczby w dec
}
int main()
{
///////////////////input
int n;
std::vector<std::string>vec;
std::cout << "podaj ilosc liczb: ";
std::cin >> n;
for (int i = 0; i < n; i++) {
std::string temp; std::cin >> temp;
vec.push_back(temp);
}
//////////////////output
std::cout << "output: " << std::endl;
for (auto iterator : vec) {
std::cout << to_result(iterator); //zwracanie pojedynczych znakow
}
std::cout << std::endl;
return 0;
_getch();
}