Witam
zrobiłem sobie ostatnio implementacje stosu, kolejki i listy w C++ i wszystko działa fajnie, ale postanowiłem porównać szybkość mojego stosu ze stosem z C++ (z biblioteki stack). I wyszły mi zaskakujące wyniki bowiem mój jest ponad 6 razy szybszy!
Mój stos:
template<class T>
class Stack
{
class Component
{
public:
T value;
Component *next_component = nullptr;
Component(T &value)
{
this->value = value;
}
};
Component *c = nullptr;
std::size_t _size = 0;
public:
const bool is_empty() const { return c == nullptr; }
const std::size_t size() const { return _size; }
void push(T value)
{
_size++;
if (c == nullptr)
{
c = new Component(value);
}
else
{
Component *temp = new Component(value);
temp->next_component = c;
c = temp;
}
}
T pop()
{
if (c == nullptr) throw std::out_of_range("Cannot pop from the stack - it is empty!");
_size--;
Component *temp = c->next_component;
T value = c->value;
delete c;
c = temp;
return value;
}
T& peek() const
{
if (c == nullptr) throw std::out_of_range("Cannot peek the stack - it is empty!");
return c->value;
}
void clear()
{
std::size_t *_ptr = &_size;
while (*_ptr) {
(*_ptr)--;
Component *temp = c->next_component;
delete c;
c = temp;
}
}
~Stack()
{
clear();
}
};
Metoda porównania:
#define SIZE 1000
#define TESTS 100
long long tab[SIZE];
void test()
{
clock_t begin_time;
float time;
begin_time = clock();
for (int i = 0; i < TESTS; i++)
{
std::stack<long long> s;
for (int j = 0; j < SIZE; j++)
s.push(tab[j]);
for (int j = 0; j < SIZE; j++)
s.top() += 50;
while (!s.empty())
s.pop();
}
time = float(clock() - begin_time) / CLOCKS_PER_SEC;
std::cout << "System's stack: " << time << endl;
begin_time = clock();
for (int i = 0; i < TESTS; i++)
{
Stack<long long> s;
for (int j = 0; j < SIZE; j++)
s.push(tab[j]);
for (int j = 0; j < SIZE; j++)
s.peek() += 50;
while (!s.is_empty())
s.pop();
}
time = float(clock() - begin_time) / CLOCKS_PER_SEC;
std::cout << "My stack: \t" << time << endl;
}
int main() {
srand(time(nullptr));
for (int j = 0; j < SIZE; j++)
tab[j] = rand();
for (int i = 0; i < 10; i++)
test();//10 testów dla pewności
getchar();
return 0;
}
Oraz wyniki:
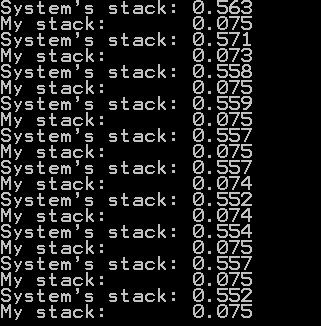
Moje pytanie brzmi: dlaczego? przecież domyślny stos powinien być lepiej zrobiony i powinien być szybszy
Pozdrawiam




